python爬虫案例:采集携程酒店数据

python爬虫案例:采集携程酒店数据
WMY-WXPython爬虫实时抓取携程酒店真实价格
:pushpin:核心信息
:paperclip:目标网站
https://hotels.ctrip.com/hotels/list
:hammer_and_wrench:环境配置
| 类别 | 说明 |
|---|---|
| Python版本 | 3.10+ |
| 开发工具 | PyCharm(推荐) |
| 关键依赖 | DrissionPage |
:package:模块安装
1 | # 核心自动化工具(推荐使用清华源加速) |
:dart:课程亮点
1.真实的商业网站数据采集实战
2.无头浏览器自动化技巧
3.反爬虫策略应对方案
4.数据存储与清洗方法
:bulb:课前准备
1.安装好Python环境
2.准备好PyCharm或VSCode
3.可提前思考想采集的酒店数据类型
爬虫实现基本流程
一.数据来源分析
1.明确需求
明确采集的网站以及数据内容
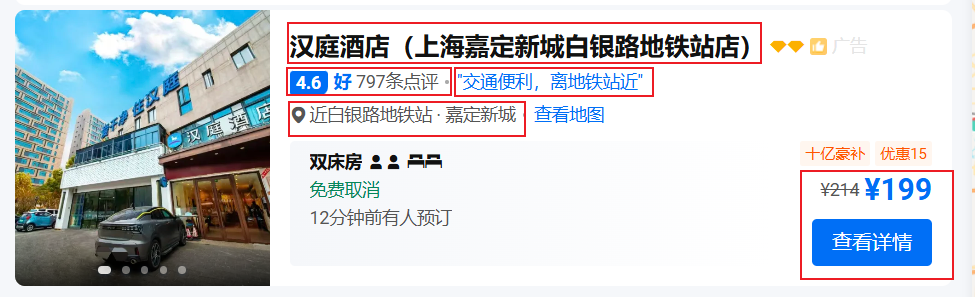
数据:酒店相关信息

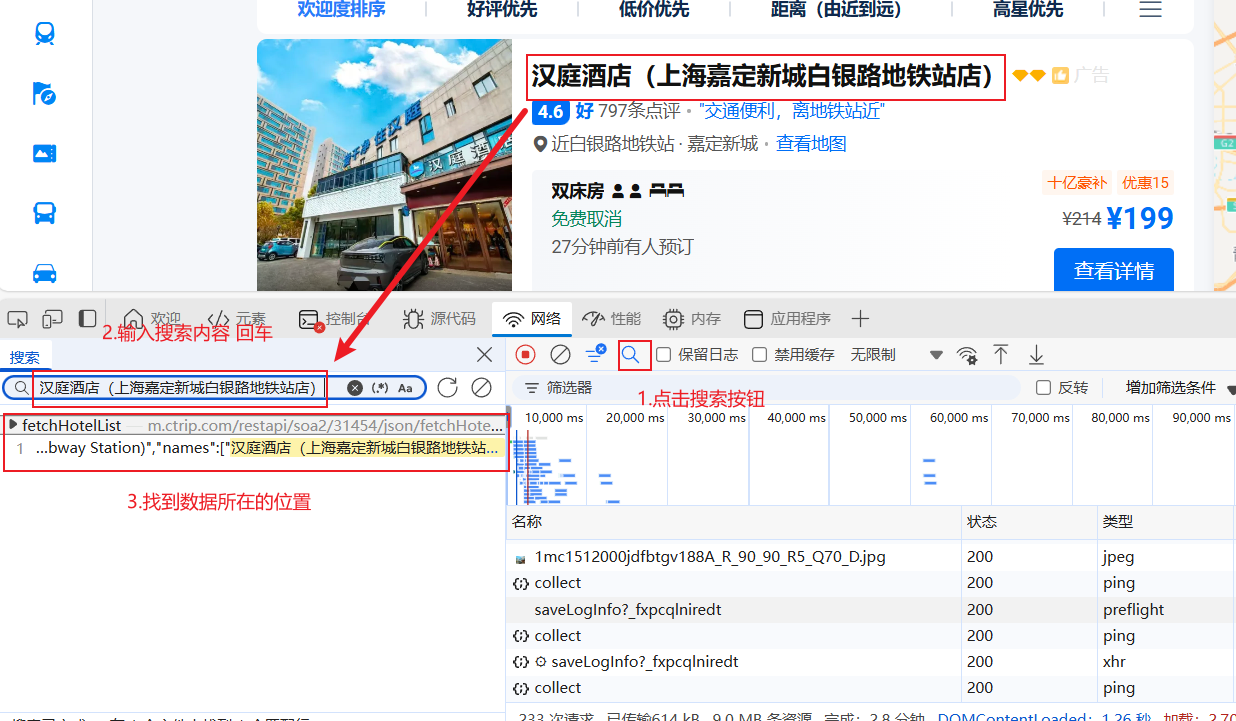
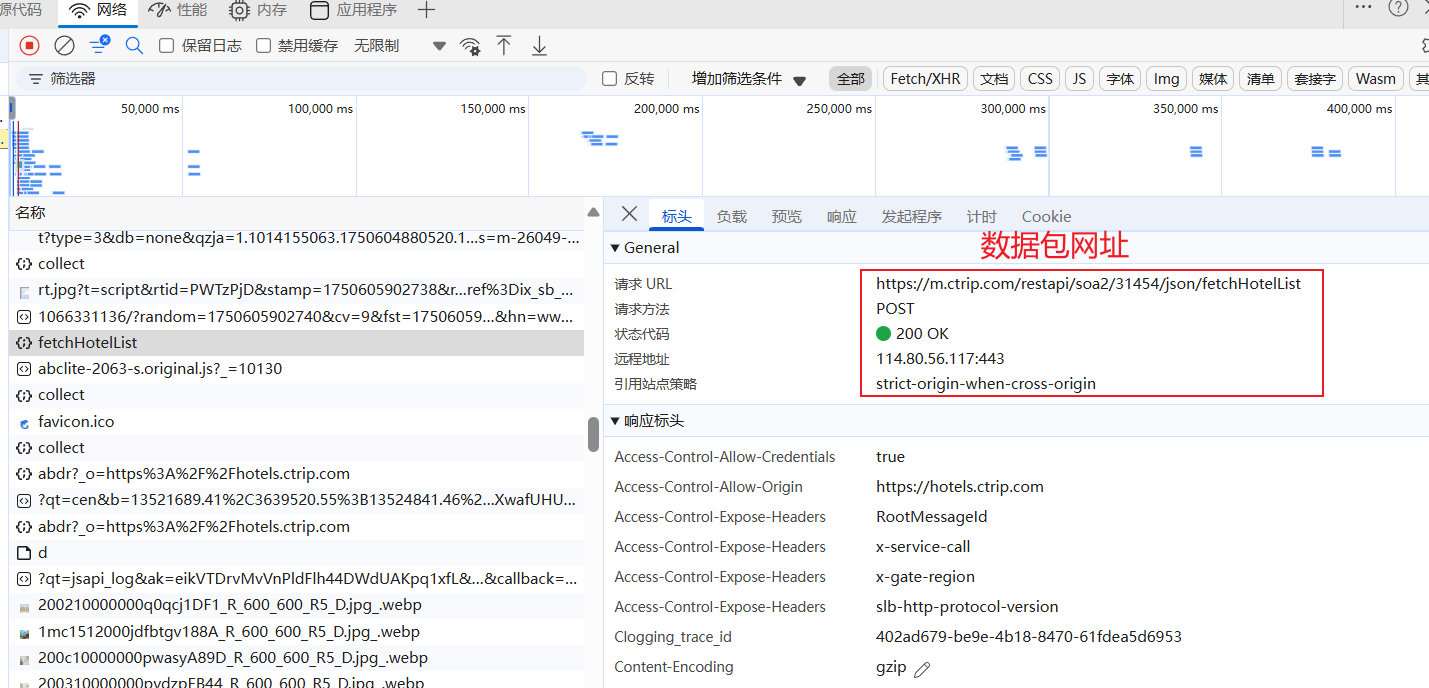
2.抓包分析
通过浏览器的开发者工具分析对应的数据位置
打开开发者工具
- F12 / 右键点击检查选择network(网络面板)
刷新网页
- 让本网页的数据内容重新加载一遍(网站数据包)
通过关键字搜索找到对应的数据位置
关键字搜索:想要什么数据就搜索什么数据